David Mertz, Ph.D.
Compactor, Gnosis Software, Inc.
February, 2002
An earlier installment of this column examined techniques by which XML documents can be reversibly restructured to improve compression. For large XML documents and embedded processes, however, restructuring an entire source prior to a compression pass might be impractical. This installment examines how well restructuring techniques can be adapted to block-level processing--both in terms of compression improvements and CPU/memory requirements.
XML documents, as is well known, tend to be quite large compared to other forms of data representation. Of course, in balance to this, the simplicity and generality of XML makes it worthwhile, despite its verboseness. Much of the time, in fact, the size of XML really makes no difference--DASD is cheap, and the time on the wire might be only a small part of the total time in the process. But at other times, bandwidth and storage space can be important.
To quantify matters, it is not at all unusual for XML documents that represent table-oriented data to be three times as large as a CSV or database representation, or even than a flat file. A similar increase is typical in representing EDI data (such as for ebXML projects). In many of these context, one starts out with multi-megabyte data sources, and making them multiple times larger can be inconvenient, especially for transmission purposes.
When one thinks about compressing documents, one normally
thinks first of general compression algorithms like Lempel-Ziv,
Huffman, Burrows-Wheeler, and of the common utilities that
implement variations on them. Examples of such utilities are
gzip, zip, and bzip2 (and library versions of each).
These utilities indeed tend substantially to reduce the size of
XML files, most especially bzip2. Fewer people are aware of
PPM techniques for compression, which can generally compress at
even higher rates than bzip2--but at the cost of an even
higher time requirement than the already sluggish bzip2. The
reigning "king of the hill" for compressing XML documents is
xmlppm, which utilizes some XML-specific techniques similar
to those presented in this column; however, xmlppm is several
orders of magnitude slower, and unboundedly more memory-hungry,
than the xml2struct presented here. But if you have the time
and memory, xmlppm achieves astonishing compression rates.
It turns out that one can obtain considerably better
compression rates by utilizing the specific structure of XML
documents to produce more compressible representations. The
XMill utility is an implementation of this technique (as is
xmlppm, in a somewhat more sophisticated way). However,
previous techniques for combining XML restructuring with
generic compression algorithms have operated at the level of
entire XML documents. This is true of XMill, of xmlppm, and
also of my original xml2stuct utility. The general
principle behind all these techniques is to to locate
relatively homogeneous parts of a document, and group them
close to each other in a transformed file. After such
grouping, standard compressors compress better (higher ratios,
but even nominally faster also). In particular, XML gives a
strong clue that portions of a document are similar by
enclosing them in same-named element tags.
If one must deal with many-megabyte XML documents, however,
spending the memory, disk space, and CPU overhead to manipulate
huge documents is often impractical. What would be nice would
be if one could take not the entire multi-megabyte source, but
only parsed blocks read serially, and apply similar techniques.
It is noteworthy to recall from the prior installment of this
column on this topic, that the Burrows-Wheeler algorithm
applied "generically" performed much of the same restructuring
that xml2struct performs using knowledge of XML (thereby with
similar compression results). However, the effectiveness of
the Burrows-Wheeler algorithm depends in large part on being
able to perform global analysis on large inputs sources--we
find in the below quantitative analysis that Burrows-Wheeler
loses all its advantages when addressing (relatively) small
serial blocks from XML documents. The restructuring-pass
techniques retain their effectiveness to a much larger degree
under this constraint.
There are a variety of practical purposes the block-level restructuring/compression techniques addressed in the paper can be put to. The very simplest case is one where XML files are relatively large (e.g. hundreds or thousands of megabytes), memory and disk-space moderately constrained (e.g. there are not gigabytes of extra memory/storage available for the process), and channel costs comparatively expensive (e.g. transmitting a half-gigabyte is a worthwhile savings over transmitting a gigabyte). The scenario for the simplest case would utilize a protocol like the below:
0. Machine A has both a channel to Machine B and a large
XML source (either a file or some dynamic generation of
XML content).
1. A SAX parser on A, "flushes" its data each time a block
worth of source XML has been encountered.
a. The flushed block is restructured.
b. The flushed block is compressed by conventional
means (i.e. 'gzip' or 'bzip2').
c. The restructured/compressed block is transmitted.
2. Machine B receives blocks over the channel. The
underlying XML is reconstructed in a serial fashion.
Each block of XML could be appended to a file; or it
could itself be fed to a SAX parser that acted on the
elements and contents (and discarded once processed).
Very little in the restructuring technique of xml2struct
needs to be changed from earlier work to accommodate arbitrary
block sizes. The article archive contains two implementations
of block-level restructuring. A Python implementation follows
closely the pattern of the xml2struct.py utility presented in
XML Matters #13--the code is also much more compact and
easier to follow. An "optimized" C implementation was also
developed to examine the speed performance of the algorithm.
In the original algorithm, a list of tags was included as the first delimited section of a restructured XML documents. This list of tags--generated on an ad hoc basis during the actual document parsing--was used as an index for single-byte tag placeholders used in a structure schematic. The strategy of using byte index value in the place of tags itself reduces the size of restructured documents somewhat, but also limits the algorithm to handling DTDs with fewer than 254 distinct tags.
Under the block-level revision below, we instead assume that a taglist is available independently. A utility function to create a taglist from a DTD is provided in the article archive. Assuming both sides of the channel have the requisite DTD, everything works--shy of a DTD, any other format that specifies the order of tags works too.
The only significant revision needed was the addition of a new (first) delimited document section to indicate current element nesting. In the original, every start tag was paired to an end tag. But since XML documents are broken at arbitrary positions, it is necessary to record a stack of "open" elements at the point a block begins. The first block parsed has an empty field for this first section; subsequent ones are likely to have one or more bytes listing tag indexes that have not yet been closed.
The format of a restructured block is rather simple:
BLOCK FORMAT: 1. List of open tags. Each start tag is a single byte (w/ byte value >= 0x03); this list is pushed on to the taglist stack to match corresponding close tag bytes. 2. A section delimiter: 0x00 (the null byte) 3. A compact representation of the block document structure, where each start tag is represented by a single byte, and the occurence of content is marked by a 0x02 byte. A close tag is represented by a 0x01 byte, and must be back-matched to corresponding start tag. 4. Another section delimiter: 0x00 (the null byte) 5. The contents of all the elements indicated in the document structure schematic, grouped by element type. Each individual content item is delimited by a 0x02 byte, while the start of elements of a new type is delimited by a 0x01 byte (the last not strictly needed, but it makes reversing the transformation easier).
Two limitations of the demonstration code should be noted. The first is purely a product of research implementation convenience. Element attributes are not handled by the current parser. This is primarily to make the presented code easier to follow, and adding like-attribute blocks would be a straightforward extension of the current technique, and are unlikely to appreciably affect compression or performance.
A second limitation is more consequential. Blocks are only
flushed when end tags are encountered. If the PCDATA content
of single elements are not consistently smaller than the block
size used, no enforcement of the block size is performed. For
example, a huge XHTML document that contained one big <pre>
element would not enforce any reasonable block size. It might
be possible to change this limitation--although doing so would
by inelegant within a SAX framework. However, there is little
point in lifting this, since reorganization will be
inconsequential for documents with element contents larger than
the block size (and should not be performed in general). The
one situation where a problem could arise is when an
implementing system has a hard limit on available memory, and
encounters a block too large to process.
In the normal case, input XML blocks will be slightly larger than the indicated block size, but once single-byte tag placeholders are substituted for tags, the resultant size will typically be slightly smaller than the block size. Moreover, once compression is applied to the block, the compressed block size will be considerably smaller than the input block size.
For purposes of quantification, I work with the same two representative XML documents addressed in my earlier research. One document was a prose-oriented document, an XML version of Shakespeare's Hamlet. The second XML source document was created from a one megabyte Apache log file, with XML tags used to surround each field of the log file (and each entry). The tags used were not particularly verbose, but the file still expanded to about 3 megabytes.
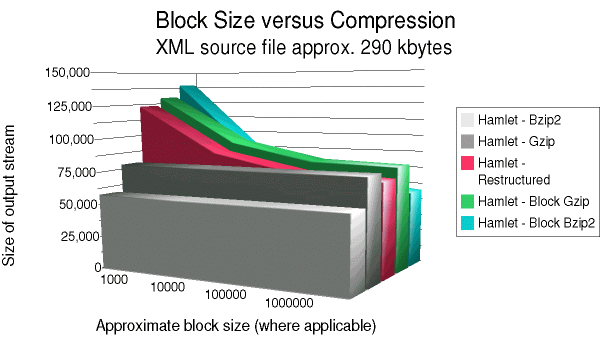
On the below graphs, the two gray bars in the front represent
the compression achievable with simple file-level compression,
using gzip and bzip2. As discussed above, file-level
compression of large files might be impractical; but as
expected, file-level compression achieves better results since
it has the whole file to look for repeated strings in. In
general, one has to get up to blocks of 100 kilobytes or
larger before the block-level compression pulls nearly even
with the file-level compression. Still, if one has to worry
about gigabyte source documents, even a megabyte block looks
pretty manageable in comparison.
The green and blue bars at the back of the graph represent the compression achievable by compressing blocks without a restructuring pass.
Finally, the red bar in the middle represents the compression
performance of xml2struct.py, combined with zlib
library compression. Better compression results would be
obtained by using the bzip2 library. This was not tested,
however, because most anticipated future uses are likely to
make the speed disadvantage of bzip2 prohibitive. However, if
bandwidth is more important than CPU time, adding a bzip2
compression layer might enhance the benefits.
Let us look at the results, then make some comments. Block sizes of 1k, 10k, 100k, and 1M were tried. First Hamlet:
Then a weblog:
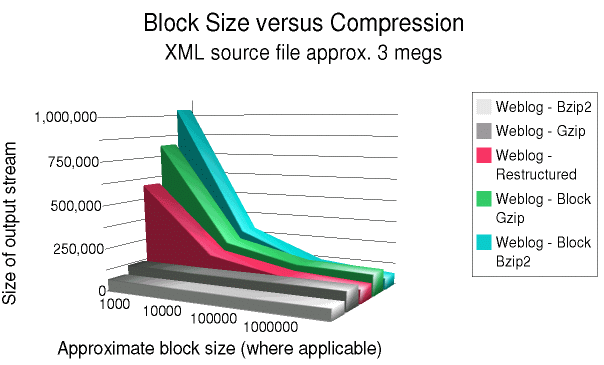
The same general pattern occurs in both the hamlet.xml and
weblog.xml--but the pattern is much stronger in
weblog.xml (the highly repetitive structure of a log file
gives restructuring its strongest advantage). At small block
sizes, compression is much worse than file-level compression.
Around 10k block size, block-level compression starts to look
moderately good; and at 100k block size it becomes very close
to the file-level compression techniques.
The aspect of the charts that is most interesting for this
paper is the compression characteristics of the restructuring
block strategy. Restructuring consistently improves on the
behavior of simple block-level zlib (around 30% for the web
log, less for Hamlet). At around 100k blocks, restructuring
does better than file-level gzip, which is a very positive
result.
A surprising result is the behavior of block-level bzip2
compression. As one would expect, once block size gets large,
it makes no difference that block-level compression is used.
But one has to get to the 1m size to wipe out the whole
difference. However, at small block sizes (1k especially, but
even at 10k), block-level bzip2 does shockingly badly. Prior
restructuring is unlikely to improve this signicantly. In
fact, for the 1k block size bzip2 is consistently much worse
than zlib.
Using the optimized C implementation of xml2struct, I
examined the speed at which restructuring and compression can
be performed. If one imagines a use of these procedures
as a channel intermediary, the ability of the process to
saturate its output channel is of crucial importance. The
times presented here were gathered using the Linux
time utility. Elapsed time of runs is reported; each run
showed close to 100% CPU usage, and was predominantly user
time. One surprise (to me) is that block size makes very
little difference to the running times of any of the examined
transformations.
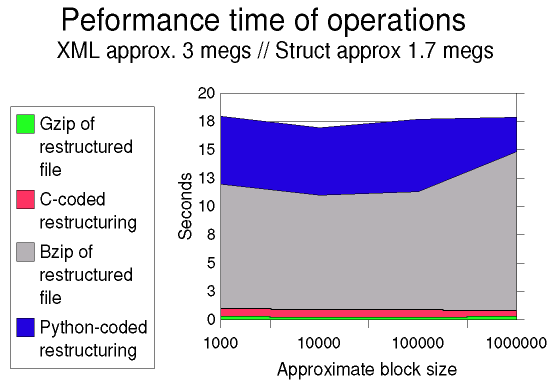
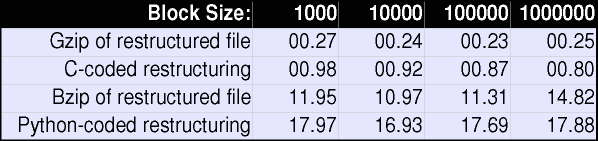
The general timing pattern is pretty clear. Restructuring (in
the C implementation) is quite fast; gzip is even faster;
bzip2 is slow (PPM, incidentally, is another 10+ times slower
than bzip2). I included the running time of the Python
implementation as a baseline. The Python version is completely
non-optimized (it could be made faster, but probably not more
than 2x). The quick summary of both the Python implementation
and a bzip2 pass is that they are too slow for most channel
saturation uses.
What do these running times mean for output channel saturation?
A three megabyte file can be restructured in slightly under a
second on a PIII-733, with block size making only a small
difference to the speed of restructuring. Compressing the
restructured file with gzip/'zlib' adds another quarter
second to the process time. This works out to approximately 20
megabits/sec; in other words, a PIII-733 performing
xml2struct'+'gzip can saturate two 10 megabit ethernet
channels, or about 13 T1 lines. A slow Pentium if dedicated to
the xml2struct process, should suffice to fill a T1 line
(which is dedicated to transmitting XML documents efficiently).
Going in the other direction, a Intel P4 or AMD Athlon running
at clock speeds over a Gigahertz, should be able to satisfy the
requirements of a 45 megabit T3 line.
The structure of documents significantly affects their
compressibility with standard compression algorithms. Since
XML encodes much detail of its semantic structure in its
syntactic form, a "restructuring" of such documents can improve
their compressibility. Moreover, this paper has shown that
such restructuring techniques are amenable to serialization
using parsed blocks from large XML documents. Moreover,
xml2struct algorithm can be implemented in optimized C with
peformance characteristics that allow it to saturate dedicated
output channels from "XML servers", using current generation
CPUs and currently common channel bandwidths.
This article is based, in large part, on two longer whitepapers written for Intel Developer Services. These (will) appear at:
http://developer.intel.com
This installment follows up on the investigation in XML Matters #13, "XML and Compression: Exploring the entropy of documents." The code and results therein provide useful background to this installment:
http://www-106.ibm.com/developerworks/library/x-matters13.html
The source code files mentioned in this article can be found in an archive at:
http://gnosis.cx/download/xml2struct.zip
The XMill XML compressor utilizes XML restructuring in a manner
generally similar to xml2struct. Information and a
downloadable version can be found at the below link. The
license requires a click-through, and the download page
unfortunately seems to have a buggy script that does not allows
downloads from all sites.
http://www.research.att.com/sw/tools/xmill/
Amazingly good (and correspondingly slow) compression of XML
documents is provided by the utility xmlppm. A discussion by
its creator, James Cheney of Cornell University, has the title
"Compressing XML with Multiplexed Hierarachical PPM Models" (it
can be found at the xmlppm website):
http://www.cs.cornell.edu/People/jcheney/xmlppm/xmlppm.html
A number of pointer to the theory and implementation of "Prediction by Partial Match" (PPM) compression can be found at:
http://DataCompression.info/PPM.shtml
The complete plays of Shakespeare can be found in XML form at
the below resource. The document hamlet.xml used for testing
purposes was obtained there:
http://www.ibiblio.org/xml/examples/shakespeare/
The 1994 paper A Block-sorting Lossless Data Compression
Algorithm, by M. Burrows and D.J. Wheeler, introduced the
algorithm known now as Burrows-Wheeler. This technique is
implemented in the fairly popular bzip2 utility:
http://gatekeeper.dec.com/pub/DEC/SRC/research-reports/abstracts/src-rr-124.html
Many Unix-like systems include bzip2 as part of their
standard distribution. For other platforms--or for newer
versions--'bzip2' can be found at:
http://sources.redhat.com/bzip2/
I wrote what I believe is a good general introduction to data compression. It can be found at:
http://www.gnosis.cx/publish/programming/compression_primer.html
David Mertz believes that less is more. David may be reached
at [email protected]; his life pored over at
http://gnosis.cx/publish/. Suggestions and recommendations on
this, past, or future, columns are welcomed.