xml.dom ModuleDavid Mertz, Ph.D.
President, Gnosis Software, Inc.
May 2000
This article examines in greater detail the use of the high-levelxml.dommodule for Python discussed in Charming Python #1. Working withxml.domis illustrated by means of clarifying code samples and explanations of how to code many of the elements that will go into a complete XML document processing system.
Python is a freely available, very-high-level, interpreted language developed by Guido van Rossum. It combines a clear syntax with powerful (but optional) object-oriented semantics. Python is available for almost every computer platform you might find yourself working on, and has strong portability between platforms.
XML is a simplified dialect of the Standard Generalized Markup Language (SGML). Many readers will be most familiar with SGML via one particular document type, HTML. XML documents are similar to HTML in being composed of text interspersed with and structured by markup tags in angle-brackets. But XML encompasses many systems of tags that allow XML documents to be used for many purposes: magazine articles and user documentation, files of structured data (like CSV or EDI files), messages for interprocess communication between programs, architectural diagrams (like CAD formats), and many other purposes. A set of tags can be created to capture any sort of structured information one might want to represent, which is why XML is growing in popularity as a common standard for representing diverse information.
The xml.dom module is probably the most powerful tool
available to a Python programmer for working with XML
documents. Unfortunately, the documentation provided by the
XML-SIG is currently a bit sparse. Some of this gap is filled
in by the W3C's language-neutral DOM specification. But it
would be nice for Python programmers to have a quick-start
guide to the DOM that is specific to the Python language. This
article aims to provide such a guide. As with "Charming Python
#1," the sample quotations.dtd files are used in some of the
samples, and are available with the article code-sample
archive.
It is worth getting a sense of exactly what DOM is. The official explanation is a good one.
The Document Object Model is a platform- and language-neutral interface that will allow programs and scripts to dynamically access and update the content, structure and style of documents. The document can be further processed and the results of that processing can be incorporated back into the presented page. (World Wide Web Consortium DOM Working Group)
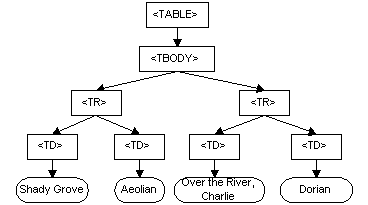
The way DOM works is by converting an XML document to a tree--or forest--representation. The W3C specification gives as an illustration a DOM version of an HTML table.
DOM defines a set of methods to traverse, prune, reorganize, output, and manipulate a tree such as this at a level of abstraction higher, and more convenient, than the underlying linearity of an XML document.
Valid HTML is almost, but not quite, valid XML. The two main
differences are that XML tags are case-sensitive, and that all
XML tags require an explicit close (as a closing tag, which is
optional for some HTML tags; or e.g., <img src="X.png" />).
A simple example of using xml.dom is to utilize the
HtmlBuilder() class to convert HTML to XML.
"""Convert a valid HTML document to XML USAGE: python try_dom1.py < infile.html > outfile.xml """ import sys from xml.dom import core from xml.dom.html_builder import HtmlBuilder # Construct an HtmlBuilder object and feed the data to it b = HtmlBuilder() b.feed(sys.stdin.read()) # Get the newly-constructed document object doc = b.document # Output it as XML print doc.toxml()
The HtmlBuilder() class is kind enough already to implement
some of the underlying xml.dom.builder template functionality
it inherits, and its source is worth looking at. However, even
where we implement template functions ourselves, the outlines
of a DOM program will be similar. In the general case, we will
build a DOM instance by some means, and then operate on that
instance. The .toxml() method of a DOM instance is a simple
way to produce a string representation of the DOM instance (in
the above case, simply to print it out once generated).
A Python programmer can achieve a great deal of power and
generality by exporting an arbitrary Python object instance as
XML. This allows us to handle Python objects in exactly the
manner we are accustomed to, with the option of eventually
using our instance attributes as tags in the generated XML.
With just a few lines (derived from the building.py example)
we can convert Python "native" objects to DOM objects, with
recursion on those attributes that are contained objects.
"""Build a DOM instance from scratch, write it to XML USAGE: python try_dom2.py > outfile.xml """ import types from xml.dom import core from xml.dom.builder import Builder # Recursive function to build DOM instance from Python instance def object_convert(builder, inst): # Put entire object inside an elem w/ same name as the class. builder.startElement(inst.__class__.__name__) for attr in inst.__dict__.keys(): if attr[0] == '_': # Skip internal attributes continue value = getattr(inst, attr) if type(value) == types.InstanceType: # Recursively process subobjects object_convert(builder, value) else: # Convert anything else to string, put it in an element builder.startElement(attr) builder.text(str(value)) builder.endElement(attr) builder.endElement(inst.__class__.__name__) if __name__ == '__main__': # Create container classes class quotations: pass class quotation: pass # Create an instance, fill it with hierarchy of attributes inst = quotations() inst.title = "Quotations file (not quotations.dtd conformant)" inst.quot1 = quot1 = quotation() quot1.text = """'"is not a quine" is not a quine' is a quine""" quot1.source = "Joshua Shagam, kuro5hin.org" inst.quot2 = quot2 = quotation() quot2.text = "Python is not a democracy. Voting doesn't help. "+\ "Crying may..." quot2.source = "Guido van Rossum, comp.lang.python" # Create the DOM Builder builder = Builder() object_convert(builder, inst) print builder.document.toxml()
The function object_convert() has a few limitations. For
example, it is impossible to produce a quotations.dtd
conformant XML document with the above procedure: #PCDATA text
cannot be placed directly inside a quotation class, but only
within an attribute of the class (such as .text). One simple
workaround would be to have object_convert() handle an
attribute named, e.g., .PCDATA in a special manner. The
conversion to DOM could be made more sophisticated in various
ways, but the beauty of the approach is that we can start with
entirely "Pythonic" objects, and convert them in a
straightforward manner to XML documents.
It is also worth noting that elements at the same level in the produced XML document will not occur in any obvious order. For example, on the author's system, using the particular version of Python he does, the second quotation defined in the source appears first in the output. But this could change between versions and systems. Attributes of Python objects are not inherently ordered to start with, so this behavior makes sense. This behavior is what we want and expect for data relating to a database-system, but is obviously not what we would want for a novel we marked up as XML (unless, perhaps, we wanted an update on William Burroughs' "cut-up" method).
It is just as easy to generate a Python object out of an XML
document as the reverse process was. In many cases, we might
well be satisfied with using xml.dom methods. But in other
situations, it is nice to use identical techniques with objects
generated from XML documents as with all our "generic" Python
objects. In the below code, for example, the function
pyobj_printer() might have been a function we already used
to handle an arbitrary Python object.
"""Read in a DOM instance, convert it to a Python object """ from xml.dom.utils import FileReader class PyObject: pass def pyobj_printer(py_obj, level=0): """Return a "deep" string description of a Python object""" from string import join, split import types descript = '' for membname in dir(py_obj): member = getattr(py_obj,membname) if type(member) == types.InstanceType: descript = descript + (' '*level) + '{'+membname+'}\n' descript = descript + pyobj_printer(member, level+3) elif type(member) == types.ListType: descript = descript + (' '*level) + '['+membname+']\n' for i in range(len(member)): descript = descript+(' '*level)+str(i+1)+': '+ \ pyobj_printer(member[i],level+3) else: descript = descript + membname+'=' descript = descript + join(split(str(member)[:50]))+'...\n' return descript def pyobj_from_dom(dom_node): """Converts a DOM tree to a "native" Python object""" py_obj = PyObject() py_obj.PCDATA = '' for node in dom_node.get_childNodes(): if node.name == '#text': py_obj.PCDATA = py_obj.PCDATA + node.value elif hasattr(py_obj, node.name): getattr(py_obj, node.name).append(pyobj_from_dom(node)) else: setattr(py_obj, node.name, [pyobj_from_dom(node)]) return py_obj # Main test dom_obj = FileReader("quotes.xml").document py_obj = pyobj_from_dom(dom_obj) if __name__ == "__main__": print pyobj_printer(py_obj)
The focus here should be on the function pyobj_from_dom(),
and specifically on the xml.dom method .get_childNodes()
which is where the real work happens. In pyobj_from_dom(),
we extract any text directly wrapped by a tag, and put it in
the reserved attribute .PCDATA. For any nested tags
encountered, we create a new attribute with a name matching the
tag, and assign a list to the attribute so we can potentially
include multiple occurances of the tag within the parent block.
By using a list, of course, we maintain the order in which tags
were encountered within the XML document.
Aside from using our old pyobj_printer() generic function (or
more likely, something more sophisticated and robust), we can
now access elements of py_obj using normal attribute
notations, e.g.
>>> from try_dom3 import * >>> py_obj.quotations[0].quotation[3].source[0].PCDATA 'Guido van Rossum, '
One of the great virtues of DOM is that it allows a programmer to manipulate an XML document in a non-linear fashion. Each block surrounded by matching open/close tags is simply a "node" in the DOM tree. While the nodes are maintained in a list-like fashion to preserve order information, there is nothing special or immutable about the order. We can easily prune off a node, and graft it back in somewhere else in the DOM tree (even at a different level, if the DTD allows this). Or add new nodes, delete existing nodes, etc.
"""Manipulate the arrangment of nodes in a DOM object
"""
from try_dom3 import *
#-- Var 'doc' will hold the single <quotations> "trunk"
doc = dom_obj.get_childNodes()[0]
#-- Pull off all the nodes into a Python list
# (each node is a <quotation> block, or a whitespace text node)
nodes = []
while 1:
try: node = doc.removeChild(doc.get_childNodes()[0])
except: break
nodes.append(node)
#-- Reverse the order of the quotations using a list method
# (we could also perform more complicated operations on the list:
# delete elements, add new ones, sort on complex criteria, etc.)
nodes.reverse()
#-- Fill 'doc' back up with our rearranged nodes
for node in nodes:
# if second arg is None, insert is to end of list
doc.insertBefore(node, None)
#-- Output the manipulated DOM
print dom_obj.toxml()
Performing the rearrangement of quotations in the above few
lines would have posed a considerable problem if we viewed an
XML document as simply a text file, or even if we used a
sequential-oriented module like xmllib or xml.sax. With
DOM, the problem is not much more difficult than any other
operation we might perform on a Python list.
Charming Pytyon #1: An Introduction to XML Tools for Python
http://gnosis.cx/publish/programming/charming_python_1.html
The Python Special Interest Group on XML:
http://www.python.org/sigs/xml-sig/
The World Wide Web Consortium's DOM page.
http://www.w3.org/DOM/
The DOM Level 1 Recommendation.
http://www.w3.org/TR/1998/REC-DOM-Level-1-19981001/
Files used and mentioned in this article:
http://gnosis.cx/download/charming_python_2.zip
David Mertz has, by this time, been writing software for a
couple decades, but has spent that same time generally writing
about quite different matters. Roads come together. The
main thing that has attracted him to Python is that in
comparison to most other programming languages it is both
aposiopetic and aphaeretic. You can just write what you mean
without the language making extra demands of your fingers.
David may be reached at [email protected]; his life pored over at
http://gnosis.cx/publish/. Suggestions and recommendations on
this, past, or future, columns are welcomed.