David Mertz, Ph.D.
Ideationist, Gnosis Software, Inc.
March 2001
This column discusses several paradigms for data modelling that are used by DBMS's. The reader is led through some advantages and disadvantages of each. Following an introduction to data-modelling concepts, David attempts to place XML within the world of data models.
XML is an extremely versitile data transport format; but despite some high hopes for it, XML is mediocre to poor as a data storage and access format. It is not nearly time to throw away your (SQL) relational databases which are tuned to quickly and reliably query complex data. So just what is the relationship between XML and the relational data model? And more specifically, how can a project that utilizes both--with data transitions between the two--be well designed? This column discusses data models as they have been abstractly theorized by computer scientists, with an eye to figuring out just how those models help us in developing specific multi-representational data flows. Future columns will look at specific code and tools to aid the transitions; this column addresses the design considerations.
Let's bracket XML for a few moments, and talk about for a bit about abstract data models. A lot of work goes into the details of a good database design, at the level of specific project requirements. We are interested in something more general than that--in paradigms of data modelling.
In broad themes, database mangagement systems (DBMSs) have been of three types historically: Hierarchical, Relational, and Object Oriented. At this same level of high generality, the three types of DBMSs occurred in the historical order listed. Hierarchical database arose in the 1960s, on mainframe data processing of the time. "Network databases" are similar to hierarchical ones, but with mutliple parent/child relations allowed. In the 1970s, the rigorous mathematical work of E.F. Codd and others created the now upiquitous Relational database model. In the 1980s--largely because of the growing popularity of object-oriented programming--Object databases gained a measure of popularity, especially to model so-called "rich data" such as multimedia formats.
Currently, Relational database management systems (RDMSs) continue to be the dominant data storage technique for large scale systems. Hierarchical and Object databases fill niche requirements. However, for many years, many popular DBMSs have been hybrid Object-Relational, so some borders between data model paradigms are blurred in practice.
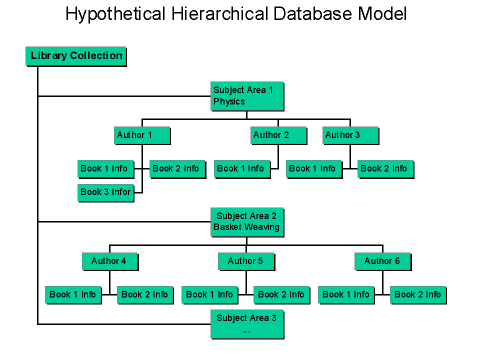
In a Hierarchical database (HDBMS), we begin with a strictly defined tree of data nodes. Each node can contain some identifying data, plus a set of subnodes of a specific child type. The number of subnodes can vary between sibling nodes at the same level, but the type of all "cousins" is identical. An illustration makes this clear:
A nice property of Hierarchical databases is that data access is utterly predictable in structure, and therefore both retrieval and updates can be highly optimized by a DBMS. For example, in the pictured model, we might determine a particular book's publisher, in a pseudo query syntax, with:
Programming/C.J.Date/An Introduction to Database Systems/Publisher?
Any such query will have a precise path to the specified datum, which may be quickly determinable in balanced trees and byte-offset codings. Any question about any books publisher will have exactly the same (unique) form, just with different category, author, etc. To continue with our hypothetical DBMS, we might write a more general procedural query in something like this (Python-like) pseudo-code:
for book in get_children("Programming/C.J.Date"):
print book.field("Title"), book.field("Publisher")
At this point, XML programmers will have started to notice that our pseudo-query syntax looks a lot like XPATH, and our procedural pseudo-code looks a fair amount like DOM. Let's keep that in mind as we go through some more models.
A Relational database consists a set of tables, where each table consists a fixed collection of columns (also called fields). An indefinite number of rows (or records) occur within each table. However, each row must have a unique primary key, which is a sort of name for that particular bundle of data. An illustration of this is worthwhile also (covering roughtly the same data as the Hierarchical example):
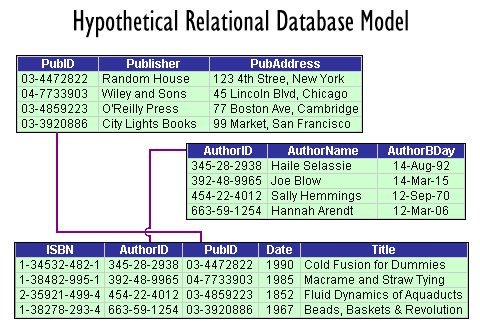
As well as having primary keys, tables typically have some secondary keys. These secondary keys correspond with primary keys in other tables. For example, in the picture, the BOOKS table has secondary keys "AuthorID" and "PubID". These, in turn, serve as primary keys for the AUTHORS and PUBLISHERS tables. The idea here is that every BOOKS row has a distinct ISBN value, each AUTHORS a unique AuthorID, and each PUBLISHERS a unique PubID.
As a constaint on the relation between tables we can state, for example, that for a row to exist in BOOKS, there must exist a row in PUBLISHERS with the PubID we want to use in BOOKS. If one publisher can "have" multiple books in this way, we call the relation "one-to-many." On the other hand, if one author can have multiple books, but one book can also have multiple authors, we call it "many-to-many." To round things out, there also exist "one-to-one" relations where one primary key must match exactly one secondary key. It is the job of RDBMSs to enforce just these types of rules.
In Relational databases, the design of tables can become quite elaborate, and involve subtle decisions. The main concern in design is for the proper normalization of tables. The goal in normalization--to condense the first through fifth "form" of normalization--is to remove all redundancy in the way data is stored. Each non-key datum should live in just one place, and nowhere else. This goal is accomplished almost automatically in Hierarchical databases, but takes work in Relational ones. For example, our picture probably has a normalization problem. If books can have multiple authors, where might we store a second author? The only real option is by creating an extra row in BOOKS. But if we do that, we need repeat an identical PubID, Date and Title just to mention a second author. Not only does this require extra storage space, it risks introducing errors if the Titles do not quite match up between the rows. To fix this, we would need to rethink our design, and probably create some more tables and relations.
Compared to the Hierarchical model, the Relational model is quite complicated. But with the complication comes a huge increase in power. You can ask essentially any question you want of an RDBMS, but only the questions designed into the system for an HDBMS. For example, suppose you wondered what authors were born later than 1970. In a HDBMS like that illustrated above, the only way to find this out would be an extremely costly search of every book leaf node. With an RDBMS you use the staightforward SQL query:
SELECT AuthorName FROM AUTHORS WHERE AuthorBDay > 1970
For a more complex question, you have to join multiple tables, but normalization allows you to do this in complex ways. For example, the above authors who publish with Random House might be queried as:
SELECT AuthorName FROM AUTHORS a, BOOKS b, PUBLISHERS p WHERE AuthorBDay > 1970 AND a.AuthorID = b.AuthorID AND b.PubID = p.PubID AND p.Publisher = "Random House"
In the query we state several relations we want to hold. Another way to think of this is as a filter on the tables, each narrowing the search. The RDBMS can implement these internally however it wants, but we can imagine the following steps (in the reverse order of the specified query; but query conditions can occur in any order):
- Narrow PUBLISHERS to only "Random House" (PubID 03-4472822);
- Only consider BOOKS with matching PubID;
- Grab the list of AuthorID's from these considered BOOKS rows;
- Of the AUTHORS rows with considered AuthorID's, how many have the right AuthorBDay?
The problem with a query like this is that it requires a number of steps, some of which can be resource intensive. Even those things that are easy in a HDBMS are likely to be relatively hard in an RDBMS. However, the things that are extremely hard in HDBMS (all but a very limited few) are only moderately hard in an RDBMS.
Object databases in some ways go back to the Hierarchical model. Objects in an ODBMS--much like objects in an OO programming language--are bundles of data and behaviors. In this sense, objects are similar to branch nodes of an HDBMS, which likewise contain a bundle of child nodes.
There are two unique features of Object databases. (1) Objects can be heterogeneous, and each contain a different collection of "owned" data; (2) Objects can contain some inherent "intelligence." Each of these features merit brief elaboration. As with the other models, let us suggest a diagram to start with:
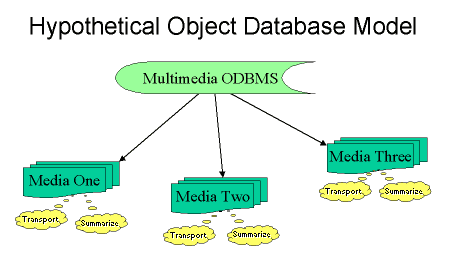
Heterogeneous objects in and ODBMS allow each bundle of data to contain just what it needs. To help with this, imagine our database is not simply the library book records that our previous models covered, but rather an actual online library whose content was delivered out of the database. Different media (sound recordings, etexts, movies, etc) will require different descriptive information from each other (as well as containing different content bitstreams). Each object is pointed to be a known ObjectID, but within the object we do not have a rigidly uniform set of child nodes as in a HDBMS.
Since objects in an ODBMS can contain a variety of attributes and data, querying objects is often performed through a set of "methods" that objects implement--but each object in a way that is appropriate for itself. In the example given, two such methods might be "summarize" and "transport." A summary of a book might be its abstact, while the summary of a movie might be a trailer. Each object has the necessary intelligence to know what a relevant way of summarizing itself is. Another way of thing of an object's "intelligence" is in terms of "meta-data" that it carries.
The Object Database Management Group (ODMG) has proposed a standard query language for ODBMS's called OQL. See Resources for details.
As readers already familiar with XML will have pieced together, XML is something of a hybrid. XML is probably most similar to Object databases in data model inasmuch as it also consists of nodes, and nodes can contain heterogeneous data. On the other hand, just how heterogeneous nodes are depends a lot on the particular DTDs or Schemas used to define the structure of an XML document. In something like XHTML or DocBook, almost any element can appear almost anywhere (this is a slight exaggeration, but it points in the right direction). But in DTDs oriented more to data records, an XML document could be as rigid as a Hierarchical database. As a transport XML is rich enough to represent either objects or hierarchies fully, given only the right DTD/Schema.
What XML is less natural in representing is Relational databases. But we should be precise about what is less natural here. XML is certainly adequate to represent anything that comes out of an RDBMS. Individual tables can be directly represented literally, albeit far more verbosely than actual RDBMS's do. For example, we might propose the following DTD to represent the BOOKS table in our example:
<?xml version="1.0" encoding="UTF-8"?> <!ELEMENT BOOKS (BOOK*)> <!ELEMENT BOOK (ISBN,AuthorID,PubID,Date,Title)> <!ELEMENT ISBN (#PCDATA)> <!ELEMENT AuthorID (#PCDATA)> <!ELEMENT PubID (#PCDATA)> <!ELEMENT Date (#PCDATA)> <!ELEMENT Title (#PCDATA)>
Schemas could be used for richer typing, but the point is that there is almost nothing involved in representing a particular RDBMS table as XML.
Similarly, any specific join we might perform (as in the above SQL examples) can equally easily be represented in XML. In practice, representing a query result is the greatest and most common use of XML for RDBMS's. I particular contact usually does not need an entire data set, but rather simply some particular filtered and structured part of it. The "GROUP BY" and "SORT" clauses in SQL allow for more structuring than we have seen, but their results are similarly well represented by XML node hierarchies.
The problem for many XML-everywhere (and XML-only) aspirations is that the core of an RDBMS are its relations. In particular, the set of constraints that exist between tables, and that are enforced by the RDBMS are what make RDBMS's so useful and powerful. While it would surely be possible to represent a constraint set in XML for purposes of communicating it, XML has no inherent mechanism for enforcing constraints of this sort (DTDs and Schemas are constraints of a sort, but in a different and more limited way). Without constraints, you just have data, not a data model (to put matters in slight caricature).
One sometimes sees the notion bandied of adding RDBMS-type constraints back into XML, and building XML into RDBMS's in some deep way. I believe that these are extremely bad ideas that arise mostly out of a "buzzword compliance" style of thinking. Major RDBMS vendors have spent many years of effort in getting these matters right--and especially to getting them right in a way that maximizes performance. You cannot just quickly tack on a set of robust and reliable relational constraints to a representation that, really, is closer to a different modelling paradigm. Moreover, the verboseness and formatting loseness of XML are at heart quite opposite to the strategies RDBMS's use to maximize performance (and to a lesser extent, reliability), such as fixed record lengths and compact storage formats. In other words, be excited by XML's promise of a universal data transport mechanism, but keep your back-end data on DB2 or Oracle (or on Postgres or MySQL for smaller scale systems).
The original paper introducing the relational data model is:
E.F. Codd, "A Relational Model of Data for Large Shared Data Banks", Comm. ACM 13 (6), June 1970, pp. 377-387.
A standard and excellent reference for learning relational database theory is:
An Introduction to Database Systems (Introduction to Database Systems, 7th Ed), C. J. Date, Addison-Wesley Pub Co, 1999. ISBN: 0201385902
Two tools the simplify working with XML in an object oriented
manner (in Python) are David Mertz' xml_objectify and
xml_pickle. You can read his earlier columns discussing
these modules at:
http://www-106.ibm.com/developerworks/library/xml-matters1/?dwzone=ws
http://www-106.ibm.com/developerworks/library/xml-matters2/index.html?dwzone=ws
The tools themselves can be found at:
http://gnosis.cx/download/xml_pickle.py
http://gnosis.cx/download/xml_objectify.py
The Object Database Management Group (ODMG) homepage can be found at the below URL. Like many places nowadays, they have information on use of XML as a data transport format.
http://www.odmg.org/
David Mertz is frequently torn between formalism and
nominalism. He suspects that spirit is a bone, but also
titters about emergent properties of skeletons. David may be
reached at [email protected]; his life pored over at
http://gnosis.cx/publish/. Suggestions and recommendations on
this, past, or future, columns are welcomed.