David Mertz, Ph.D.
Comparator, Gnosis Software, Inc.
June 2003
Fredrik Lundh'sElementTreemodule is an increasingly popular API for light-weight and fast manipulation of XML documents within Python. In this installment, I contrastElementTreewith several other libraries devoted to processing XML instances as object trees, especially with my owngnosis.xml.objectifymodule.
I have written several installments of this column in the past
that have looked at XML libraries whose aim is to emulate the
most familiar native operations in a given programming language.
The first of these that I covered is my own
gnosis.xml.objectify, for Python. I also dedicated installments
to Haskell's HaXml and Ruby's REXML. Although I have not
discussed them here, Java's JDOM and Perl's XML::Grove also
have similar goals.
Lately I have noticed a number of posters to the
comp.lang.python newsgroup mentioning Fredrik Lundh's
ElementTree as a "native" XML library for Python. Of course,
Python already has several XML API's included in its standard
distribution--there is a DOM module, a SAX module, an expat
wrapper, and the deprecated xmllib. Of these, only xml.dom
converts an XML document into an in-memory object that can be
manipulated with method calls on nodes. Actually, there are
several different Python DOM implementation, each with somewhat
different properties: xml.minidom is a basic one; xml.pulldom
builds accessed subtrees only as needed, 4Suite's cDomlette
(Ft.Xml.Domlette) builds a DOM tree in C, avoiding Python
callbacks for speed.
Of course, appealing to my author's vanity, I am most curious to
compare ElementTree to my own gnosis.xml.objectify, to which
it is closest in purpose and behavior. The goal of ElementTree
is to store representations of XML documents in data structures
that behave in pretty much the way you think about data in
Python. The focus here is on programming in Python, not on
adapting your programming style to XML.
My colleague Uche Ogbuji has previously written a short article
on ElementTree for another publication. One of the tests he ran
was comparing the relative speed and memory consumption of
ElementTree versus DOM. Uche chose to use his own cDomlette
for the comparison. Unfortunately, I am unable to install 4Suite
1.0a1 on the Mac OSX machine I am working on (I have mentioned
this issue to Uche before, I am not sure if there is yet a
resolution or workaround). However, we can use Uche's estimates
to guess likely performance--he indicates that ElementTree is
30% slower, but 30% more memory-friendly, than Ft.Xml.Domlette.
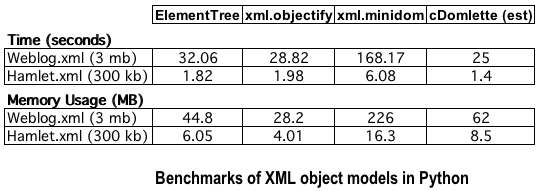
Mostly I was curious how ElementTree compares in speed and
memory to gnosis.xml.objectify. I have actually never
benchmarked my module very precisely before, since I never had
anything concrete to compare it to. I selected two documents
that I have used for benchmarking in the base: a 289 kB XML
version of Hamlet and a 3 mB XML web log. I created scripts
that simply parse an XML document into the object models of the
various tools, but do not perform any additional manipulation:
% cat time_xo.py import sys from gnosis.xml.objectify import XML_Objectify,EXPAT doc = XML_Objectify(sys.stdin,EXPAT).make_instance() --- % cat time_et.py import sys from elementtree import ElementTree doc = ElementTree.parse(sys.stdin).getroot() --- % cat time_minidom.py import sys from xml.dom import minidom doc = minidom.parse(sys.stdin)
Creating the program object is quite similar in all three
cases, and also with Ft.Xml.Domlette. I estimated memory
usage by watching the output of top in another window; each
test was run 3 times to make sure they were consistent, and the
median value was used (memory was identical across runs).
One thing that is clear is that xml.minidom quickly becomes
quite impractical for moderately large XML documents. The rest
stay (fairly) reasonable. gnosis.xml.objectify is the most
memory-friendly, but that is likely because it does not
preserve all the information in the original XML instance
(data content is kept, but not all structural information).
I also ran the following test of Ruby's REXML, using the
following script:
require "rexml/document" include REXML doc = (Document.new File.new ARGV.shift).root
REXML proved about as resource intensive as xml.minidom:
parsing Hamlet.xml took 10 seconds and used 14 MB; parsing
Weblog.xml took 190 seconds and used 150 MB. Obviously, the
choice of programming language usually comes before the
comparison of libraries for them.
A nice thing about ElementTree is that it can be
round-tripped. That is, you can read in an XML instance,
modify fairly native-feeling data structures, then call the
.write() method to re-seralize to well-formed XML. DOM does
this, of course, but gnosis.xml.objectify does not. It is
not all that difficult to construct a custom output function
for gnosis.xml.objectify that produces XML--but doing so is
not automatic. With ElementTree, along with the .write()
method of ElementTree instances, individual Element
instances can be serialized with the convenience function
elementtree.ElementTree.dump(). This lets you write XML
fragments from individual object nodes--including from the root
node of the XML instance.
I present a simple task that contrasts the ElementTree and
gnosis.xml.objectify APIs. The large weblog.xml document
used for benchmark tests contains about 8500 <entry>
elements, each having the same collection of child fields--a
typical arrangement for a data-oriented XML document. A
particular task in processing this file might be to collect a
few fields from each entry, but only if some other fields have
particular values (or ranges, or match regexen, etc). Of
course, if you really only want to perform this one task, using
a streaming API like SAX avoids the need to model the whole
document in memory--but let us assume that this task is one of
several being performed on the large data structure by an
application. One <entry> element looks something like:
<entry> <host>64.172.22.154</host> <referer>-</referer> <userAgent>-</userAgent> <dateTime>19/Aug/2001:01:46:01</dateTime> <reqID>-0500</reqID> <reqType>GET</reqType> <resource>/</resource> <protocol>HTTP/1.1</protocol> <statusCode>200</statusCode> <byteCount>2131</byteCount> </entry>
Using gnosis.xml.objectify, I might write a filter-and-extract
application as:
from gnosis.xml.objectify import XML_Objectify, EXPAT
weblog = XML_Objectify('weblog.xml',EXPAT).make_instance()
interesting = [entry for entry in weblog.entry
if entry.host.PCDATA=='209.202.148.31'
and entry.statusCode.PCDATA=='200']
for e in interesting:
print "%s (%s)" % (e.resource.PCDATA,
e.byteCount.PCDATA)
List comprehensions are quite convenient as data filters. In
essence, ElementTree works the same way:
from elementtree import ElementTree
weblog = ElementTree.parse('weblog.xml').getroot()
interesting = [entry for entry in weblog.findall('entry')
if entry.find('host').text=='209.202.148.31'
and entry.find('statusCode').text=='200']
for e in interesting:
print "%s (%s)" % (e.findtext('resource'),
e.findtext('byteCount'))
There are a few differences to note above. gnosis.xml.objectify
attaches subelement nodes directly as attributes of nodes (every
node is of a custom class named after the tag name).
ElementTree, on the other hand, uses methods of the Element
class to find child nodes. The method .findall() returns a list
of all matching nodes; .find() returns just the first match;
.findtext() returns the text content of a node. If you only
want the first "match" on a gnosis.xml.objectify subelement,
you just need to index it, e.g.: node.tag[0]. But if there is
only one such sublement, you can also refer to it without the
explicit indexing.
But in the ElementTree example, we do not really need to find
all the <entry> elements explicitly, Element instances behave
in a list-like way when iterated over. A point to note is that
iteration is over all child nodes, whatever tag they may have.
In contrast, a gnosis.xml.objectify node has no built-in
method to step through all of its subelements. Still, it is
easy to construct a one-line children() function (I will
include one in future releases). Contrast:
>>> open('simple.xml','w.').write('''<root>
... <foo>this</foo>
... <bar>that</bar>
... <foo>more</foo></root>''')
>>> from elementtree import ElementTree
>>> root = ElementTree.parse('simple.xml').getroot()
>>> for node in root:
... print node.text,
...
this that more
>>> for node in root.findall('foo'):
... print node.text,
...
this more
With:
>>> children=lambda o: [x for x in o.__dict__ if x!='__parent__']
>>> from gnosis.xml.objectify import XML_Objectify
>>> root = XML_Objectify('simple.xml').make_instance()
>>> for tag in children(root):
... for node in getattr(root,tag):
... print node.PCDATA,
...
this more that
>>> for node in root.foo:
... print node.PCDATA,
...
this more
As you can see, gnosis.xml.objectify currently discards
information about the original order of interpersed <foo> and
<bar> elements (it could be remembered in another magic
attribute, like .__parent__ is, but no one has had the need
and/or sent a patch to do this).
ElementTree stores XML attributes in a node attribute called
.attrib. The attributes are stored in a dictionary.
gnosis.xml.objectify puts the XML attributes directly into
node attributes of corresponding name. The style I use tends
to flatten the distinction between XML attributes and element
contents--to my mind that is something for XML to worry about,
not for my native data structure to worrry about. For example:
>>> xml = '<root foo="this"><bar>that</bar></root>'
>>> open('attrs.xml','w').write(xml)
>>> et = ElementTree.parse('attrs.xml').getroot()
>>> xo = XML_Objectify('attrs.xml').make_instance()
>>> et.find('bar').text, et.attrib['foo']
('that', 'this')
>>> xo.bar.PCDATA, xo.foo
(u'that', u'this')
There is still some distinction in gnosis.xml.objectify
between XML attributes that create node attributes containing
text, and XML element contents that create node attributes
containing objects (perhaps with subnodes having .PCDATA).
ElementTree implements a subset of XPATH in its .find*()
methods. Using this style can be much more concise than
nesting code to look within levels of subnodes, especially for
XPATHs containing wildcards. For example, if I was interested
in all the timestamps of hits to my web server, I could examine
weblog.xml using:
>>> from elementtree import ElementTree
>>> weblog = ElementTree.parse('weblog.xml').getroot()
>>> timestamps = weblog.findall('entry/dateTime')
>>> for ts in timestamps:
... if ts.text.startswith('19/Aug'):
... print ts.text
Of course, for a shallow and regular document like
weblog.xml, it is easy to do the same thing with list
comprehensions:
>>> for ts in [ts.text for e in weblog
... for ts in e.findall('dateTime')
... if ts.text.startswith('19/Aug')]:
... print ts
Prose-oriented XML documents, however, tend to have much more
variable document structure, and typically nest tags at least
five or six levels deep. An XML schema like DocBook or TEI,
for example, might have citations in sections, subsections,
bibliographies, sometimes within italics tags, or in
blockquotes, and so on. Finding every <citation> element
would require a cumbersome (probably recursive) search across
levels. Or using XPATH, you could just write:
>>> from elementtree import ElementTree
>>> weblog = ElementTree.parse('weblog.xml').getroot()
>>> cites = weblog.findall('.//citation')
The XPATH support, however, in ElementTree is limited. You
cannot use the various functions contained in full XPATH, nor
can you search on attributes. In what it does though,
the XPATH subset in ElementTree greatly aids readability and
expressiveness.
I want to mention one more quirk of ElementTree before I wrap
up. XML documents can be mixed content. Prose-oriented XML, in
particular, tends to intersperse PCDATA and tags rather freely.
But where exactly should you store the text that comes
between child nodes. Since an ElementTree Element instance
has a single .text attribute--which contains a string--that
does not really leave space for a broken sequence of strings.
The solution ElementTree adopts is to give each node a
.tail attribute which contains all the text after a closing
tag, but before the next element begins or the parent element
is closed. For example:
>>> xml = '<a>begin<b>inside</b>middle<c>inside</c>end</a>'
>>> open('doc.xml','w').write(xml)
>>> doc = ElementTree.parse('doc.xml').getroot()
>>> doc.text, doc.tail
('begin', None)
>>> doc.find('b').text, doc.find('b').tail
('inside', 'middle')
>>> doc.find('c').text, doc.find('c').tail
('inside', 'end')
ElementTree is a nice effort to bring a much lighter weight
object model to XML processing in Python than that provided by
DOM. Although I have not addressed it in this article, but
ElementTree is equally good at generating XML documents from
scratch as it is at manipulating existing XML data.
As author of a similar library, gnosis.xml.objectify, I cannot
be entirely objective in evaluating ElementTree; but
nonetheless, I continue to find my own approach somewhat more
natural in Python programs than that provided by ElementTree.
The latter still usually utilizes node methods to manipulate data
structures rather than directly accessing node attributes as one
usually does with data structures built within an application.
However, in several areas, ElementTree shines. It is far easier
to access deeply nested elements using XPATH than with manual
recursive searches. Obviously, DOM also gives you XPATH, but
at the cost of a far heavier and less uniform API. All the
Element nodes of ElementTree act in a consistent manner,
unlike DOMs panoply of node types.
The home page for ElementTree is:
http://effbot.org/zone/element.htm
IBM developerWorks columnist Uche Ogbuji discussed
ElementTree for XML.com in a February 2003 article:
http://www.xml.com/lpt/a/2003/02/12/py-xml.html
XML Matters #2 introduced gnosis.xml.objectify, then called
simply xml_objectify.
XML Matters #11 updates readers to some early improvements to
gnosis.xml.objectify. Some newer features have not been
covered in this column, but are in the module's HISTORY and
other documentation files.
XML Matters #14 discussed the HaXml module for the Haskell
lazy pure-functional programming language.
XML Matters #18 discussed Ruby's REXML library.
Dave Kuhlman has developed another Python XML API/library called
generateDS. He has written a very nice essay comparing
generateDS with gnosis.xml.objectify at:
http://www.rexx.com/~dkuhlman/gnosis_generateds.html
In brief, the idea behind generateDS is to use an XML Schema as
the basis for Python classes that properly handle the elements in
an XML instance. Rather than handle XML trees generically,
generateDS is code generator for Python modules to handle
specific XML document schemas--autogenerated code can easily be
specialized to quickly form a custom application. Read more
about the library at:
http://www.rexx.com/~dkuhlman/generateDS.html
For David Mertz an atomic object is a combination of facts.
David may be reached at [email protected]; his life pored over at
http://gnosis.cx/publish/. Suggestions and recommendations on
this, past, or future, columns are welcomed. Check out David's
new book Text Processing in Python.